Het releasemoment van APEX 5 komt naderbij.
Ik heb zojuist een mail ontvangen van het Oracle Apex support team waarin gewaarschuwd wordt om de applicaties op de early adopter 2 site veilig stellen omdat deze omgeving zal worden vervangen door de early adaptor 3 versie. Eerder is ook gesproken over een public beta versie die door een geselecteerde groep gebruikers kan worden getest op hun eigen site. Ik ben benieuwd hoe breed beschikbaar deze versie komt want het zou heel goed zijn om je eigen applicaties te kunnen upgraden en zo APEX 5 verder te testen.

Inmiddels zijn maar liefst 6028 workspaces op de early adapter 2 site aangemaakt. Zie dit twitter bericht van Joel R. Kallman.

Ik kan niet wachten om met de ThemeRoller aan de gang te gaan. Het lijkt mij super handig om je theme kleuren te kunnen opbouwen vergelijkbaar met de ThemeRoller van jQuery UI.
Buffer sort madness
Last week I was called in on a performance issue regarding a query on a datawarehouse that took about 4 hours. When looking at the execution plan in the excellent sql monitor I noticed a big full table scan yielding a whopping 125 million rows. Before I could turn around to ask the application team why this table was not partitioned my eyes were drawn to the cpu usage and wait bars in the plan. The buffer sort on the result of the full table scan was taking far more time than the scan itself!
I have seen this phenomenon a long time ago and I wouldn’t have thought this issue would still be around in the 11g r2 database.

The culprit in this is the cartesian join. The query contained a cartesian join to a calendar table which was filtered on a single day. The result in this case is that the 125 million rows are put in a sort area for the buffer sort. The sort area is way to small to hold these rows and so we end up doing this on disk using temp.
The approach the optimizer took is probably to prevent the full table to be repeated in case the cardinality estimate on the calendar was off, but the result is pretty dramatic. When I forced the use of a nested loops join the buffer sort was gone. What is left is that in 11g r2 the optimizer apparently still doesn’t have the capability to forsee the cost of the buffer sort disk operation.
For now there doesn’t seem to be an elegant way to work around this, maybe the adaptive query optimisation of 12c will resolve this in a better way.
De eeuwige strijd: middleware versus applicatieIedereen die te maken heeft gehad met integratie vraagstukken herkent het volgende probleem: plaatsen we de logica van de vertalingen in de middleware of in de applicatie? Ik heb zelf talloze uren gespendeerd aan deze discussie. Hele whiteboards werden dan vol geschreven met de pro’s en con’s van beide keuzes. Wat mij altijd opvalt bij deze discussies is de verbetenheid waarmee deze worden gevoerd. Het mondt vaak uit in een stammenstrijd waarin voor- en tegenstanders hun kampen betrekken en elkaar bestrijden met principes.
De applicatie-aanhangers vinden dat alle business logica tot het applicatie domein behoort. De middleware dient ‘onwetend’ te zijn en alleen te worden gebruikt als (geavanceerde) transportlaag.
De middleware-aanhangers vinden dat alle mogelijkheden van hun tools moeten worden benut. Dat is nou juist de kracht van de middleware. En daar is al veel geld voor betaald. Dus dan moet je het ook goed gebruiken.
Een principe-strijd dus. Al spelen politieke en commerciële belangen natuurlijk ook een grote rol bij het innemen van een standpunt. Het probleem van een dergelijke principe-strijd is dat beide standpunten zeer goed te verdedigen zijn. En dat niemand dus het absolute gelijk aan zijn zijde heeft. Helaas zijn dat precies de omstandigheden waarin mensen niet van hun standpunt willen afwijken. De stellingen zijn betrokken en niemand geeft elkaar een duimbreed toe.
Het zou helpen als er op een andere manier naar dit probleem gekeken zou worden. Voor zowel middleware als applicaties geldt dat deze bestaan omdat ze organisaties moeten faciliteren bij het realiseren van hun IT-processen. Het zijn dus beiden middelen en geen doelen op zich. Principale discussies hierover zijn dus weinig zinvol. Dergelijke discussies zijn relevant als je het hebt over doelen. Maar niet als je het hebt over middelen.
Het is mijn overtuiging dat bij de keuze tussen middleware versus applicatie vooral moet worden gekeken naar waar de organisatie het best in is. Stel dat je allemaal Oracle maatwerk applicaties hebt draaien en je hebt een fantastisch ingerichte IT-organisatie die zeer bedreven is in het bouwen en beheren hiervan. Dan lijkt het mij voor de hand liggen dat je alle logica in de applicaties aanbrengt. Daar ligt immers jouw kracht. En als je juist een heel divers IT-landschap hebt met verschillende technologieën, dan loont het wellicht om de logica in de middleware te leggen. Dan leg je daar jouw focus neer en zorg je ervoor dat je een competente middleware beheer-organisatie inricht. Dan zit daar jouw kracht en organiseer je van daaruit de grip en controle op jouw IT-landschap.
Kiezen tussen middleware versus applicatie? Kijk naar waar je goed in bent. Bedenk vooral wat jij het best en het goedkoopst kan organiseren. Laat je vooral niet verblinden door te veel principes. En als je een keuze hebt gemaakt, houd je daar dan ook aan. Dat houdt het simpel en overzichtelijk. En dat is een groot goed!
Progress database converteren naar Oracle
Zoals zoveel programmeurs heb ik in verleden als vriendendienst een applicatie voor een bevriende ondernemer gemaakt. In de tijd dat ik dit project heb uitgevoerd werkte ik hoofdzakelijk in een Progress omgeving. Het is dus niet verwonderlijk dat de applicatie daar ook in gemaakt is. Dit is een Progress 6, character based applicatie die nu hard aan vervanging toe is. Aangezien ik Progress al jaren geleden achter me heb gelaten en gekozen heb om mij te specialiseren in Oracle APEX, ben ik van plan om de applicatie te herbouwen in Oracle APEX. Een belangrijke reden om in APEX te bouwen is dat de nieuwe applicatie platform en device onafhankelijk zal moet werken. Het is niet de bedoeling om de oude applicatie één op één te kopiëren. Omdat het zonde is om de kennis die de afgelopen jaren in de applicatie is opgebouwd zomaar weg te gooien, heb ik besloten om het schema opnieuw aan te maken en aan te passen waar nodig. Dit in een Oracle database, rekening houdend met de naam conventies zoals wij die gebruiken in ons Orcado ontwikkel framework (OFW) voor Oracle (er is ook een PHP versie). Dit schema moet zoveel mogelijk gevuld moeten worden met de data uit de Progress database. Het is uiteraard mogelijk om zelf een export programma in Progress te schrijven en een import programma in PL/SQL, maar waarom het wiel opnieuw uitvinden? Ik ben op zoek gegaan naar een beschikbare tool hiervoor en die heb ik gevonden in Pro2XMLSchema.
Met deze tools is het mogelijk om het schema en de data van de Progress database te exporteren en in een Oracle database, maar ook vele andere databases, te importeren. Het gebruik van de tool is heel simpel. De tool werkt op basis van de Command Line Interface (CLI) versie van PHP (min versie 4.3). Deze zal dus aanwezig moeten zijn. Kijk hier om PHP te downloaden en te installeren. Ik ga geen uitgebreide uitleg geven over hoe je PHP en de tool moet gebruiken, dat staat in de documentatie die met de tools wordt meegeleverd. Wel zal ik kort de stappen doornemen die uiteindelijk voor de conversie zorgen. Pro2XMLSchema levert een aantal bestanden op voor de conversie van je database.
Start in de Progress ontwikkel omgeving het door Pro2XMLSchema Progress 4gl, pro2xml.p, programma voor de export van het schema en de data
Eerst wordt het schema en daarna de data geëxporteerd. Ik heb ervoor gekozen om geen indexdefinities mee te exporteren, hierover later meer. Dit programma moet 2 keer runnen. Één keer om het schema te exporteren en één voor de data. Selecteer voor het starten welke tabellen er allemaal mee moeten naar Oracle. Het eindresultaat, diversen XML-bestanden, staat in c:\temp\test directory (in mijn voorbeeld). Het TEST bestand wordt door pro2xml.p aangemaakt om te testen of in de doel directory kan worden geschreven, let er dus op dat deze directory wel aanwezig is.
Nu moeten de bestanden die zijn aangemaakt worden ingelezen. Zoals al eerder gemeld is er een nieuw schema aangemaakt waar nieuwe velden zijn toegevoegd en andere zijn vervallen en waar gebruik gemaakt wordt van een andere naam conventie. De data kan dus niet één op één in het nieuwe schema worden geladen. Daarom is er gebruik gemaakt van een staging schema waar het Progress schema met data zal worden ingelezen. Dit is ook de reden waarom de indexen niet zijn meegenomen. In de stagin zijn we zijn alleen in de data geïnteresseerd. Voor het inlezen zijn 2 PHP programma’s beschikbaar
Loadschema.php zorgt voor het laden van het schema en loaddata.php voor het laden van de data. Zorg dat de juiste gegevens in dbconnect.inc staan zodat PHP de Oracle database kan benaderen. Indien er tijdens het inlezen fouten voorkomen dan worden deze in een bestand met de naam <table>.log in de directory waar de xml data bestanden staan geplaatst. Tijdens het inlezen heb ik 2 fouten vastgesteld.
Het eind resultaat is een kopie van de Progress database in de Oracle database.
De volgende stap is een PL/SQL package in Oracle maken waarin de data uit de staging omgeving netjes en gecontroleerd wordt overzet naar het nieuwe schema. In dit nieuwe schema wordt in tegenstelling tot het Progress schema met technische sleutels gewerkt. In dit package worden de volgende acties uitgevoerd:
Nu heb ik een prima uitgangssituatie waarmee ik de nieuwe applicatie in Oracle APEX kan gaan bouwen. Deze applicatie wil ik natuurlijk graag in APEX 5 maken maar deze versie is helaas nog beschikbaar voor download. Ik denk dat ik nu eerst ga starten in de op dit moment beschikbare versie en later de applicatie zal upgraden. Volgens mij moet dit voor de toekomst genoeg stof opleveren voor een vervolg op dit verhaal.
Oracle Apex 5 EAEen hele korte blog tussendoor met naar mijn mening wel heel goed nieuws.
Voor hen die het gemist hebben, er is een early adaptor versie van Oracle Apex 5 beschikbaar.
Je kan een workspace aanvragen via deze link.
Nu nog afwachten tot versie 5 als echte release wordt vrijgegeven.
My First APEX plug-in
In an attempt to reach a broader audience, this will be my first blog in English. I hope this will help more people to read and use my tips and tricks. For me it will be an extra challenge!
For some time now (since version 4.0), APEX has offered the plug-in functionality and although I used several plug-ins, I still did not build any myself. This is mainly because existing plug-ins were adequate or I built the needed functionality directly into the application. To be able to reuse code, it is better to use plug-ins instead of coding everything into pages. In this blog I will build my first plug-in.
The purpose of the plug-in is to display notifications that can be controlled by a dynamic action. As a basis I will use the noty jQuery plug-in (http://needim.github.io/noty/) which is a good start to build the APEX plug-in around.
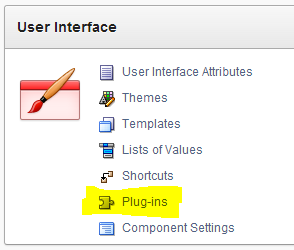
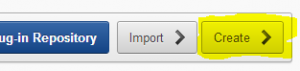
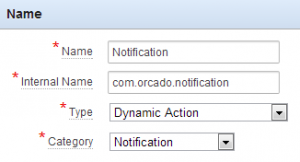
How to start? First, go to the shared components of your application and click on plug-ins under the User Interface heading. So far for the easy part ;-), although building a plug-in is not that complicated I discovered to my surprise. I will guide you through the different steps below.
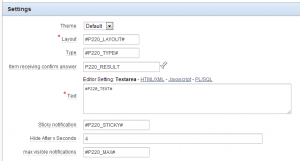
| Label | Type | Required | Depending on | Description |
| Theme | Select list | yes | Select one of the themes you have created or use the default. | |
| Layout | Text | yes | Where does the notification pop-up | |
| Type | Text | yes | alert, succes, error, warning, information or confirm | |
| Text | Textarea | yes | The text for the notification. | |
| Sticky notification | Text | no | Will the notification stick on the page. | |
| Hide after x seconds | Integer | no | Hide the notification after x seconds, only for not sticky notifications. | |
| Max visible notifications | Text | no | The maximum number of visible notifications. More will be queued and become visible when other notifications disappear. | |
| Item receiving confirm answer | Page Item/ Column | no | Item for confirm answer (Ok/Cancel) |
/**
* Notification plugin v1.0 – http://www.orcado.nl
*
* Based on jQuery plugin noty
* noty – jQuery Notification Plugin v2.1.2
* Contributors: https://github.com/needim/noty/graphs/contributors
* Examples and Documentation – http://needim.github.com/noty/
* Licensed under the MIT licenses:
* http://www.opensource.org/licenses/mit-license.php
*
**/
function com_orcado_notification(){
function replacePlaceholders(pText) {
// replace all #page_item_name# placeholders
var lSearchPattern = new RegExp(“#w+#”, “g”),
lFoundList,
lPageItem,
lFinalText = pText;
// search as long as the text contains a placeholder
while (lFoundList = lSearchPattern.exec(pText)) {
// get value, but search without the #
lPageItem = $x(lFoundList[0].replace(/#/g, “”));
if (lPageItem) {
lFinalText = lFinalText.replace(lFoundList[0], $v(lPageItem));
}
}
return lFinalText;
}; // replacePlaceholders
// It’s better to have named variables instead of using
// the generic ones, makes the code more readable
var lTheme = this.action.attribute01,
lLayout = this.action.attribute02,
lType = this.action.attribute03,
lText = this.action.attribute04,
lSticky = ((this.action.attribute05===”Y”)?false:this.action.attribute06*1000),
lMax = this.action.attribute07;
lAnswer = this.action.attribute08;
if (replacePlaceholders(lType)==’confirm’) {
var n = noty({
text: replacePlaceholders(lText).replace(/n/g,’
‘),
type: replacePlaceholders(lType),
dismissQueue: true,
layout: replacePlaceholders(lLayout),
theme: lTheme,
timeout: lSticky,
maxVisible: replacePlaceholders(lMax),
buttons: [
{addClass: ‘btn btn-primary btn-noty-ok’, text: ‘Ok’, onClick: function($noty) {
$s(lAnswer, ‘Ok’);
$noty.close();
}
},
{addClass: ‘btn btn-danger btn-noty-cancel’, text: ‘Cancel’, onClick: function($noty) {
$s(lAnswer, ‘Cancel’);
$noty.close();}
}
]
});
}
else { var n = noty({
text: replacePlaceholders(lText).replace(/n/g,’
‘),
type: replacePlaceholders(lType),
dismissQueue: true,
layout: replacePlaceholders(lLayout),
theme: lTheme,
timeout: lSticky,
maxVisible: replacePlaceholders(lMax)
});
}
}
First, we assign the generic variables to named ones. This is not required but it makes the code more readable. Then we call the noty plug-in with the right parameters. As you can see, a bit of Javascript knowledge is needed here.
| Name | Description |
| com_orcado_jquery.noty.js | Javascript wrapper around the noty jquery plug-in |
| custom.js | Custom theme (based on default.js) |
| default.js | Default theme |
| jquery.noty.js | noty jquery plug-in |
| layout.js | Javascript which will set the css for the available layouts |
function render_noty_notification (
p_dynamic_action in apex_plugin.t_dynamic_action,
p_plugin in apex_plugin.t_plugin )
return apex_plugin.t_dynamic_action_render_result
is
l_theme varchar2(4000) := p_dynamic_action.attribute_01;
l_layout varchar2(4000) := p_dynamic_action.attribute_02;
l_type varchar2(4000) := p_dynamic_action.attribute_03;
l_text varchar2(4000) := p_dynamic_action.attribute_04;
l_sticky varchar2(4000) := p_dynamic_action.attribute_05;
l_wait_seconds number := to_number(p_dynamic_action.attribute_06);
l_max varchar2(4000) := p_dynamic_action.attribute_07;
l_answer varchar2(4000) := p_dynamic_action.attribute_08;
l_result apex_plugin.t_dynamic_action_render_result;
begin
— During plug-in development it’s very helpful to have some debug information
if apex_application.g_debug then
apex_plugin_util.debug_dynamic_action (
p_plugin => p_plugin,
p_dynamic_action => p_dynamic_action );
end if;
— Register the javascript and CSS library the plug-in uses.
apex_javascript.add_library (
p_name => ‘jquery.noty’,
p_directory => p_plugin.file_prefix,
p_version => null );
apex_javascript.add_library (
p_name => ‘com_orcado_jquery.noty’,
p_directory => p_plugin.file_prefix,
p_version => null );
apex_javascript.add_library (
p_name => ‘default’,
p_directory => p_plugin.file_prefix,
p_version => null );
apex_javascript.add_library (
p_name => ‘layout’,
p_directory => p_plugin.file_prefix,
p_version => null );
— Register the function and the used attributes with the dynamic action framework
l_result.javascript_function := ‘com_orcado_notification’;
l_result.attribute_01 := l_theme;
l_result.attribute_02 := l_layout;
l_result.attribute_03 := l_type;
l_result.attribute_04 := l_text;
l_result.attribute_05 := l_sticky;
l_result.attribute_06 := l_wait_seconds;
l_result.attribute_07 := l_max;
l_result.attribute_08 := l_answer;
return l_result;
end render_noty_notification;

Na een vraag op het oracle forum over het converteren van valuta, heb ik besloten om hier een plug-in voor te schrijven.
De plug-in is niet echt heel spannend maar doet wel wat die moet doen.
Op basis van de koers die opgehaald wordt bij rate-exchange.appspot.com wordt de berekening uitgevoerd. Dit is een gratis webservice die de koers als JSON formaat terug geeft. Hier zat meteen de grootste uitdaging. Door de “same-origin policy” standaard mag je in javascript geen sites buiten het aanroepend domein benaderen. Wat je doet is een “Cross-origin resource sharing” aanroep en dat mag dus niet.
De aanroep resulteert in een “No ‘Access-Control-Allow-Origin’ header is present on the requested resource.” error.
Een uitzondering hierop wordt gemaakt indien de URL via JSONP kan worden aan geroepen. Door het toevoegen van “&callback=?” aan de URL werkt de site van rate-exange op die manier. Nu krijg je wel de JSON data binnen.
De code hiervoor ziet er dan alsvolgt uit
var url = “http://rate-exchange.appspot.com/currency?from=”+$v(action.attribute01)+”&to=”+$v(action.attribute02)+”&callback=?”;
jQuery.ajax({ type: “GET”,
url: url ,
dataType: “json”,
success: function(data) {
$s(action.attribute04,($v(action.attribute03)*data.rate).toFixed(2));
}
});
Waarbij action.attributeXX de parameters van de plug-in zijn.
Voor de selectlists van de valuta keuzes wilde ik ook een webservice gebruiken. Dit hoeft niet via javascript maar kan “gewoon” door een select die de (XML) data van de webservice kan vertalen. Er is een webservice met deze informatie beschikbaar bij de ISO organisatie via deze URL.
Dit werkt op apex.oracle.com echter niet, omdat je er een ACL voor moet aanmaken die toestemming geeft om de externe site te benaderen. In de demo gebruik ik dan ook STATIC selectlists.
Kijk op apex-plugin.com om de plugin te downloaden en hier voor een demo ervan.
Notification plug-in
Today I published a new version (1.1) of my notification plug-in.
In this version I added the possibility using free form text or predefined select lists for a few parameters.
Visit apex-plugin.com to get it.
Het gemak van xmltypeHeel af en toe krijgt een 3rd party applicatie waar wij hier beheer voor doen een fout item via een xml message binnen.
Hiervoor biedt de applicatie een beheerscherm waar de xml aangepast kan worden en daarna opnieuw aangeboden kan worden.
Dat voldeed prima tot we er op een dag ineens 90 foute berichten kregen.
Een blik op de onderliggende Oracle database liet zien dat de berichten met foutmelding in een tabel opgeslagen worden.
Zowel de errorstack als de message staan in een clob veld.
Wat we wilden automatiseren was een node uit de xml knippen waar het betreffende item uit de foutmelding in voor kwam.
Het wordt dus een update statement op de betreffende message tabel waarbij we de payload aanpassen:
| update message_error_log lg set lg.payload = ? |
Eerst identificeren we de juiste berichten in de where clause. We weten het messagetype en de foutmelding:
| where lg.message_type = 1234 and lg.exception_type = ‘com.exception.ItemNotFoundException’ |
Het vinden van het itemnummer in de foutmelding kan met ouderwets knippen en plakken:
| to_char (substr (lg.stacktrace , instr (lg.stacktrace, ‘item does not exist:’) + 19 , ( instr (lg.stacktrace , ‘at com.backend.process’ ) – 2 ) – (instr (lg.stacktrace, ‘item does not exist:’) + 19) ) ) |
Eventueel zou bovenstaande ook met een reguliere expressie kunnen.
Om zeker te zijn dat het gevallen van dit specifieke probleem zijn controleren we of het itemnummer in de xml op de juiste plaats voorkomt:
| and extractvalue (xmltype (lg.payload) , ‘/Message/Payload/Forecast/ItemDemand/itemNo[.=”‘ || to_char (substr (lg.stacktrace , instr (lg.stacktrace, ‘item does not exist:’) + 19 , ( instr (lg.stacktrace , ‘at com.backend.process’ ) – 2 ) – (instr (lg.stacktrace, ‘item does not exist:’) + 19) ) ) || ‘”]’ ) is not null |
Eerst wordt hier de clob in een xmltype gezet: xmltype (lg.payload)
Vervolgens wordt een xpath expressie gemaakt met het item uit de foutmelding:
‘/Message/Payload/Forecast/ItemDemand/itemNo[.=”<itemnummer>”]’
Hiermee wordt gecontroleerd of het betreffende nummer op de juiste plaats in de xml voorkomt.
Deze waarde wordt dan met extractvalue eruit geplukt.
Nu hebben we de juiste rijen te pakken en komt het knippen in de xml:
| update message_error_log lg set lg.payload = deletexml (xmltype (lg.payload) , ‘/Message/Payload/Forecast/ItemDemand[itemNo=”‘ || to_char (substr (lg.stacktrace , instr (lg.stacktrace, ‘item does not exist:’) + 19 , ( instr (lg.stacktrace , ‘at com.backend.process’ ) – 2 ) – (instr (lg.stacktrace, ‘item does not exist:’) + 19) ) ) || ‘”]’ ).getclobval () |
Eerst weer converteren naar xmltype: xmltype (lg.payload)
Dan met een iets andere xpath expressie op zoek naar de node waarin het item voorkomt (let op de plaats van de blokhaken!):
‘/Message/Payload/Forecast/ItemDemand[itemNo=”<itemnummer>”]’
Met deletexml wordt de betreffende node eruit geknipt.
Wat rest is de xmltype weer terug in een clob te veranderen, dit kan met de methode getclobval van het xmltype: .getclobval ()
Het eindresultaat:
| update message_error_log lg set lg.payload = deletexml (xmltype (lg.payload) , ‘/Message/Payload/Forecast/ItemDemand[itemNo=”‘ || to_char (substr (lg.stacktrace , instr (lg.stacktrace, ‘item does not exist:’) + 19 , ( instr (lg.stacktrace , ‘at com.backend.process’ ) – 2 ) – (instr (lg.stacktrace, ‘item does not exist:’) + 19) ) ) || ‘”]’ ).getclobval () where lg.message_type = 1234 and lg.exception_type = ‘com.exception.ItemNotFoundException’ and extractvalue (xmltype (lg.payload) , ‘/Message/Payload/Forecast/ItemDemand/itemNo[.=”‘ || to_char (substr (lg.stacktrace , instr (lg.stacktrace, ‘item does not exist:’) + 19 , ( instr (lg.stacktrace , ‘at com.backend.process’ ) – 2 ) – (instr (lg.stacktrace, ‘item does not exist:’) + 19) ) ) || ‘”]’ ) is not null |
In de applicatie konden we nu alle berichten opnieuw aanbieden en ze waren verwerkt.
Deze generieke oplossing kan vervolgens voor alle toekomstige gevallen gebruikt worden.
Dit bespaart tijd en is minder foutgevoelig dan het handmatige aanpassen.
Zoals zo vaak bij het schrijven van een blog item wordt deze meestal getriggerd door een probleem waar ik tijdens het werk tegen aanloop. Ook dit item is er weer een uit die categorie.
De foutmelding die ik doorkreeg was net zo simpel als kort “De zoek opdracht op pagina xx performed niet goed”.
Ik hou wel van dit soort meldingen omdat het altijd weer een leuke uitdaging is om een performance probleem op te lossen en het resultaat direct bemerkt wordt door de klant.
select ..
, ..
, its.its_oni_package.oni_radio_group_score(p_score_type =>ind.ind_score_type, .. )
from its_onderzoek_indicatoren oni
where ..
De query is voor de leesbaarheid versimpeld. De query heb ik naar sqldeveloper gekopieerd om wat makkelijker te kunnen testen. Als eerst maar eens die functie uit query gehaald en jawel hoor de query performde meteen prima. Weer een stapje dichter bij het probleem. Dan maar eens die functie uitpluizen. In de functie zit een cursor die gebruik maakt van de nv()functie.
select .. from its_onderzoek_indicatoren oni . . join ios_elementen elm on oni.oni_one_elm_id = elm.elm_id where oni.oni_one_ond_nr = nv('p10105_ond_nr') and elm.elm_id = nv('p10105_element')
Voor het gemak heb ik deze functies vervangen door bind variabelen in mijn sqldeveloper query en ik kon geen performance probleem vaststellen. huuh, hoe kan dat nu? Het blijkt dat ik het probleem al opgelost had voordat ik exact wist wat het was.
select .. from its_onderzoek_indicatoren oni . . join ios_elementen elm on oni.oni_one_elm_id = elm.elm_id where oni.oni_one_ond_nr = :p10105_ond_nr and elm.elm_id = :p10105_element
het is duidelijk dat het gebruik van nv() functie het performance probleem creëert.
select .. from its_onderzoek_indicatoren oni . . join ios_elementen elm on oni.oni_one_elm_id = elm.elm_id where oni.oni_one_ond_nr = (select nv('p10105_ond_nr') from dual) and elm.elm_id = (select nv('p10105_element') from dual)
Hier komt de sidebar