27-07-2017 door: Marlies de Bruijn
Gelukkig heeft Daan in zijn vorige blog al gezegd dat ik niet ook zo’n heel verhaal aan elkaar hoef te ratelen, pfew. Het enige waar ik voor moet zorgen is dat je na afloop het woordgrapje uit de vorige blog begrijpt. En dat er tussendoor nog iets over een lerend algoritme is uitgelegd.
Om boter-kaas-en-eieren te leren maak ik gebruik van een algoritme dat heel kort door de bocht als volgt kan worden uitgelegd. Stel dat je geen idee hebt hoe boter-kaas-en-eieren werkt. In plaats van het je vriendelijk uit te leggen, gaan we gewoon spelen. Wel vertel ik je dat je alleen maar kruisjes mag zetten, op plekken waar nog geen kruisjes of rondjes staan. Na een tijdje laat ik je weten dat het spel is afgelopen en dat je hebt verloren. In theorie kan je natuurlijk ook hebben gelijk gespeeld of zelfs hebben gewonnen, maar hé, je kende de regels nog niet en ik wel, dus daar ga ik niet vanuit. Vervolgens spelen we het nog een keer. En dat nog heel erg vaak. In de loop van tijd krijg je door hoe je kan voorkomen dat je verliest, of misschien zelfs hoe je kan winnen.
Nu is het waarschijnlijk dat jij door zou krijgen dat er een relatie is tussen 3 rondjes of kruisjes op een rij, en winst of gelijkspel of verlies. Dat is niet hoe mijn AI het doet. Mijn AI maakt gebruikt van een algoritme met de naam Q-learning, en is een variant van reinforcement learning. Je zou nu het woordgrapje moeten snappen, dan kan ik me richten op het uitleggen van het lerende algoritme. Het idee achter reinforcement learning is dat je leert door middel van de feedback die wordt geleverd, in dit geval dus of je hebt verloren, gelijk gespeeld, of gewonnen. Deze bot kan je hier uitproberen – http://undercover.horse/tictacque/ !
Reinforcement learning is gebaseerd op het behaviourism, dit is een stroming in de psychologie over gedrag. Hierin wordt gekeken hoe gedrag ontstaat onder invloed van de omgeving. Dit is een goed voorbeeld van hoe ideeën uit de psychologie worden gebruikt bij kunstmatige intelligentie. Reinforcement learning doet het meest denken aan (operante) conditionering. Hierin wordt in een bepaalde context op een bepaald gedrag altijd een beloning of straf gegeven, op die manier leert een dier of mens wat wenselijk gedrag is.
Het voordeel van Q-learning is dat je van tevoren niet hoeft te weten welke situaties kunnen voorkomen, en dus ook de bijbehorende mogelijke acties niet kent. Om te leren, wordt er een lijst bijgehouden met alle situaties die zijn tegengekomen inclusief welke zet hierin is gedaan, en een getal dat aangeeft hoe goed de uitkomst was. Die laatste is de q-waarde. Met deze lijst kan je later in dezelfde situatie dus zetten vergelijken, en degene met de hoogste q-waarde kiezen. Maar aan het begin van het spel is deze lijst helemaal leeg. Je moet dus q-waarden gaan leren.
De q-waarde wordt na iedere beurt geüpdatet, op basis van wat de q-waarde op dat moment is, en de nieuwe informatie. Deze nieuwe informatie bestaat uit de feedback, dus hoe goed de zet was, en wat de toekomstige mogelijkheden zijn. Bij boter-kaas-en-eieren is het eerste moment van feedback officieel pas als het spel is afgelopen. Hier is winst +1 punt, verlies -1, en gelijkspel 0. Daarnaast geef ik ook 0 punten aan een spel dat nog niet is afgelopen. Hoe goed de toekomstige mogelijkheden zijn, wordt bepaald door de hoogste q-waarde van de situatie waar je in bent beland. Als je het spel dus voor de eerste keer speelt, weet je pas iets als het is afgelopen. De waardes bij alles tot het einde blijven dan 0, terwijl de laatste situatie + actie wordt geüpdatet aan de hand van de feedback. Op die manier leer je steeds een stukje verder terug wat wel en geen goede zetten zijn.
Een van de gevaren hiervan is dat je een suboptimale strategie leert. Daarom is het belangrijk om te onderzoeken of er nog meer mogelijkheden zijn. Eén van de andere gevaren, is dat je altijd blijft rondkijken voor betere mogelijkheden. In dat geval weet je wel hoe je het spel perfect moet spelen, maar maak je nooit gebruik van deze kennis. Om dit te voorkomen wordt een andere lijst bijgehouden, met hoe vaak een combinatie van situatie en actie zijn voorgekomen. Als je in een situatie komt, waarin je de volgende zet moet kiezen, wordt er voor alle mogelijke zetten die minder dan 3 keer zijn gedaan niet uitgegaan van een q-waarde, maar van een gezonde nieuwsgierigheid. Op het moment dat dan de q-waarde wordt opgevraagd, wordt een optimistische waarde teruggegeven, in plaats van wat de q-waarde op dat moment is (als die dan al bestaat).
Wat je bij voorkeurAI1 ziet, is dat mijn algoritme, die ik QlearningAI heb genoemd, aan het begin van het spel alles een keer probeert, maar na een tijdje constant dezelfde tactiek uitvoert. Dat ziet er als volgt uit:
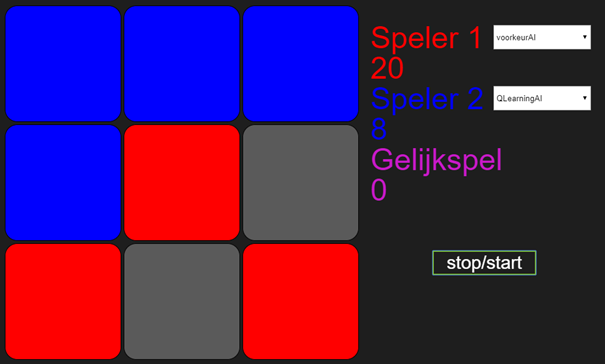
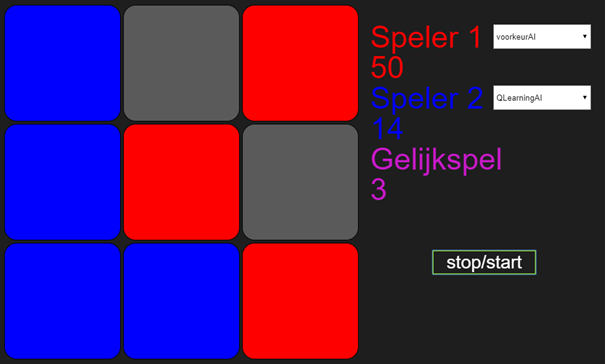
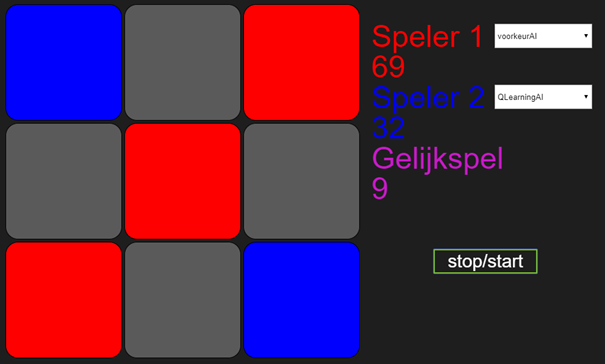
Wat je ziet is dat de VoorkeurAI1 aan het begin nog de meeste spelletjes wint, maar vanaf 69 gewonnen spellen, wint QLearningAI alles.
Tegen VoorkeurAI2 gebeurt bijna hetzelfde, behalve dat VoorkeurAI2 een tactiek heeft om verlies tegen te gaan. De QLearningAgent wint daarom niet alles, maar het wordt constant gelijk spel, zoals getoond in de volgende plaatjes.
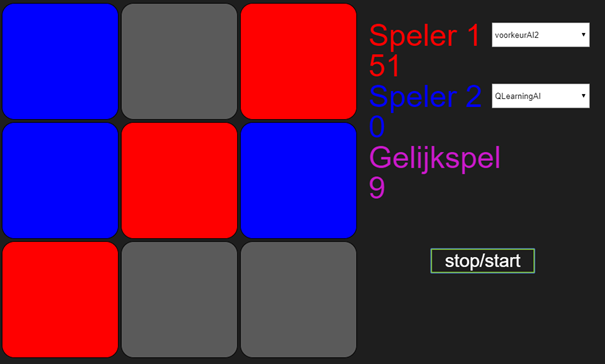

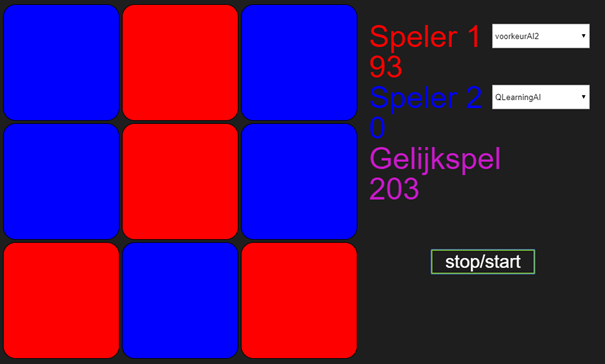
Mij vallen hier drie dingen in op. Ten eerste dat QLearningAI er tegen VoorkeurAI2 langer over doet om nooit meer te verliezen in vergelijking met VoorkeurAI1. Ik denk dat dit komt door het verschil in feedback tussen winst en gelijkspel, waardoor er sneller wordt geleerd als er wordt gewonnen. Ten tweede valt me op dat QLearningAI veel sneller dan GeneticAI2 van Daan leert tegen VoorkeurAI2. Als laatste, daarentegen, lukt het GeneticAI2 uiteindelijk wel om te winnen van VoorkeurAI2, terwijl QlearningAI blijft hangen in gelijkspel. Hopelijk is dit laatste geen voorbode voor de uitkomst als onze algoritmes het tegen elkaar opnemen…
Een van de grote verschillen tussen de voorkeurAI-algoritmen aan de ene kant, en lerende algoritmen zoals de GeneticAI2 en QLearningAI, is dat de voorkeurAI-algoritmen nooit van tactiek wisselen. Zodra de QlearningAI dus de beste strategie heeft bepaald tegen een VoorkeurAI, zal hij die altijd blijven uitvoeren. Echter, als een lerend algoritme, zoals GeneticAI2, merkt dat een andere strategie beter is, past hij zich aan. Als een resultaat hiervan, zullen de q-waarden van QLearningAI zich zo aanpassen dat ook deze van strategie veranderd. Zoals je begrijpt is mijn voorspelling dat we ons de hele tijd aan elkaar zullen aanpassen. We gaan het meemaken, alleen nog niet in de volgende blog, want dan mengt ook Roelof zich in de strijd. Roelof, je hebt nog één maand!